What?
Measuring the repetitiveness and predictability of source code, and comparing it to that of natural language.
Why?
Natural language is rich and complex but the majority of utterances fall in a fairly restricted and repetitive set of words. This allows the use of statistical models instead of formal language models. The assumption here is that source code follows a similar pattern, which might be accentuated by its even more rigid structure.
As statistical language models have enabled huge success in translation, generation, search, … if the assumption of naturalness holds true the same progress could be made with source code.
How?
RQ1: Do n-gram models capture regularities in software?
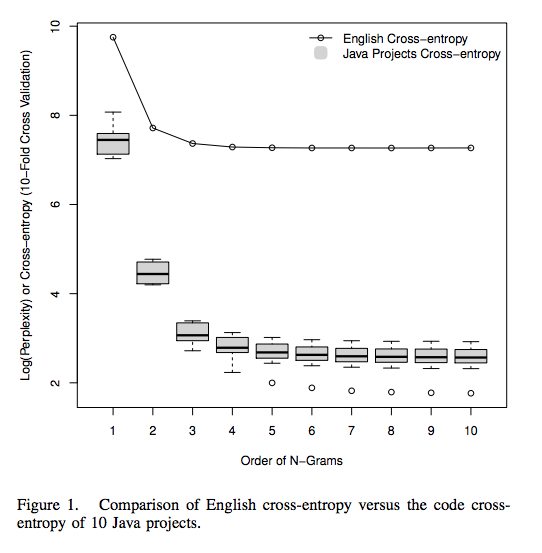
Build n-gram models of large text and source-code datasets and compute the cross-entropy of code (comparing how surprising an unseen document is compared to the rest of the corpus). The authors compare English cross-entropy vs code cross-entropy and find that “software is far more regular than English”.
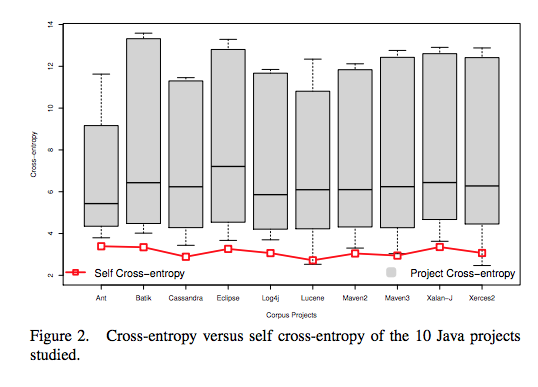
RQ2: Is the local regularity that the statistical LM captures merely language-specific or is it also project-specific?
Evaluate cross-entropy across different software projects, finding that structure is project-specific. In other words each software group carries strong local structure but not a global pattern.
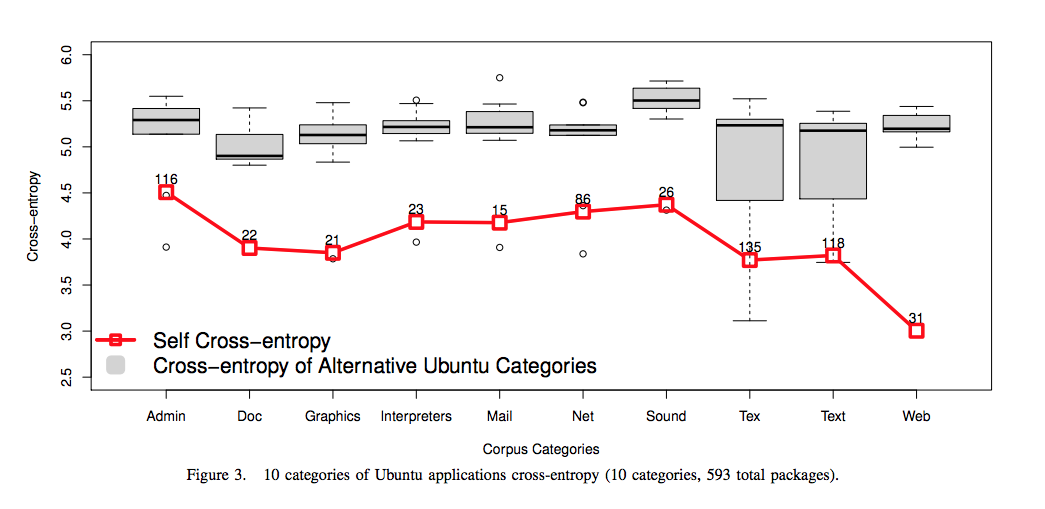
RQ3: Do n-gram models capture similarities within and differences between project domains?
The authors compare the cross-entropies of application domains within a project, finding that local regularities do appear within application domains, and much less across. This means there is an influence of the software’s function, not just its form.
Evaluation
- Text corpora
- Brown corpus
- Gutenberg Corpus
- Software corpora
- 10 Java projects
- 10 Ubuntu applications
The authors also apply their findings in the design of a code-completion extension for Eclipse, which is shown to provide improvements over the built-in engine (it is however shown to have a dependency on the length of the proposed token but does not just propose reserved keywords, demonstrating its ability to encapsulate context).
Comments
- More of a comment on the usage of code than on its nature. Then again that is what enabled NLP to be so efficient: do away with theoretical models of language to focus on how it is used.
- No comparison of project and domain-based cross-entropies for text.
- Nicely written paper, often answering a question that arises in reading in the following section.
- The regularity of software is not so surprising, but the fact that it goes beyond pure structure is interesting.
- Would have liked to see a comparison of the suggestion ranks of proposed words in the code-completion setting.
- More discussion about the “non-language-specific” tokens being proposed: are the class names, variable names? How are the predictions distributed?
- Funny quote from the paper: “Every time a linguist leaves our group the performance of our speech recognition goes up” - Fred Jelenik
Selected references
-
“A study of the uniqueness of source code”, by Gabel and Su ↩
-
“Data Mining for Software Engineering”, by Tao et al. ↩
-
“Evaluating a Software Word Usage Model for C++”, by Malik et al. ↩
-
“IDE 2.0: collective intelligence in software development”, by Bruch et al. ↩
-
“What’s in a Name? A Study of Identifiers”, by Lawrie et al. ↩